Memory Module#
The memory system in Mesa-LLM provides different types of memory implementations that enable agents to store and retrieve past events (conversations, observations, actions, messages, plans, etc.). Memory serves as the foundation for creating agents with persistent, contextual awareness that enhances their decision-making capabilities. The memory module contains two classes.
Usage in Mesa Simulations#
from mesa_llm.llm_agent import LLMAgent
from mesa_llm.memory.st_lt_memory import STLTMemory
class MyAgent(LLMAgent):
def __init__(self, model, reasoning, **kwargs):
super().__init__(model, reasoning, **kwargs)
# Override default memory with custom configuration
self.memory = STLTMemory(
agent=self,
short_term_capacity=10, # Store 10 recent experiences
consolidation_capacity=3, # Consolidate when 13 total entries
llm_model="openai/gpt-4o-mini",
display=True, # Display the memory entries in the console when they are added to the memory
api_base=None, # Set to a custom URL for self-hosted LLMs
)
Core memory interfaces#
- class MemoryEntry(content: dict, step: int | None, agent: LLMAgent)[source]#
Bases:
objectA data structure that stores individual memory records with content, step number, and agent reference. Each entry includes rich formatting for display. Content is a nested dictionary of arbitrary depth containing the entry’s information. Each entry is designed to hold all the information of a given step for an agent, but can also be used to store a single event if needed.
- class Memory(agent: LLMAgent, llm_model: str | None = None, display: bool = True, api_base: str | None = None, additive_event_types: list[str] | set[str] | tuple[str, ...] | None = None)[source]#
Bases:
ABCGeneric parent class for memory backends.
- Attributes:
agent : the agent that the memory belongs to llm_model : the model to use for the summarization if used display : whether to display the memory additive_event_types : event types that accumulate multiple values
within a step. Defaults to
{"message", "action"}.- Content Addition
Before each agent step, the agent can add new events to the memory through add_to_memory(type, content) so that the memory can be used to reason about the most recent events as well as the past events.
During the step, content for types in
additive_event_typesis accumulated as a list; all other types overwrite the previous value for that step.At the end of the step, the memory is processed via process_step(), managing when memory entries are added,consolidated, displayed, or removed
- Default behavior
By default,
additive_event_types == {"message", "action"}.Repeated
messageoractionentries within one step are accumulated as a list.Repeated
observationorplanentries within one step overwrite the previous value unless configured otherwise.
Initialize the memory
- Args:
agent : the agent that the memory belongs to llm_model : the model to use for summarization display : whether to display memory entries in the console api_base : the API base URL to use for the LLM provider additive_event_types : event types that should accumulate multiple
values within the same step instead of overwriting. Defaults to
{"message", "action"}. For example,messageandactionaccumulate by default, whileobservationandplanoverwrite unless explicitly included here.
- abstractmethod get_prompt_ready() str[source]#
Get the memory in a format that can be used for reasoning
- abstractmethod get_communication_history() str[source]#
Get the communication history in a format that can be used for reasoning
- abstractmethod process_step(pre_step: bool = False)[source]#
A function that is called before and after the step of the agent is called. It is implemented to ensure that the memory is up to date when the agent is starting a new step.
/!If you consider that you do not need this function, you can write “pass” in its implementation.
- add_to_memory(type: str, content: dict)[source]#
Add a new entry to the memory.
Event types in
self.additive_event_typesaccumulate multiple values within the same step. All other types use overwrite semantics. By default,self.additive_event_types == {"message", "action"}. For example, repeatedmessageentries are stored as a list, while repeatedobservationentries overwrite the previous value.
Memory implementations#
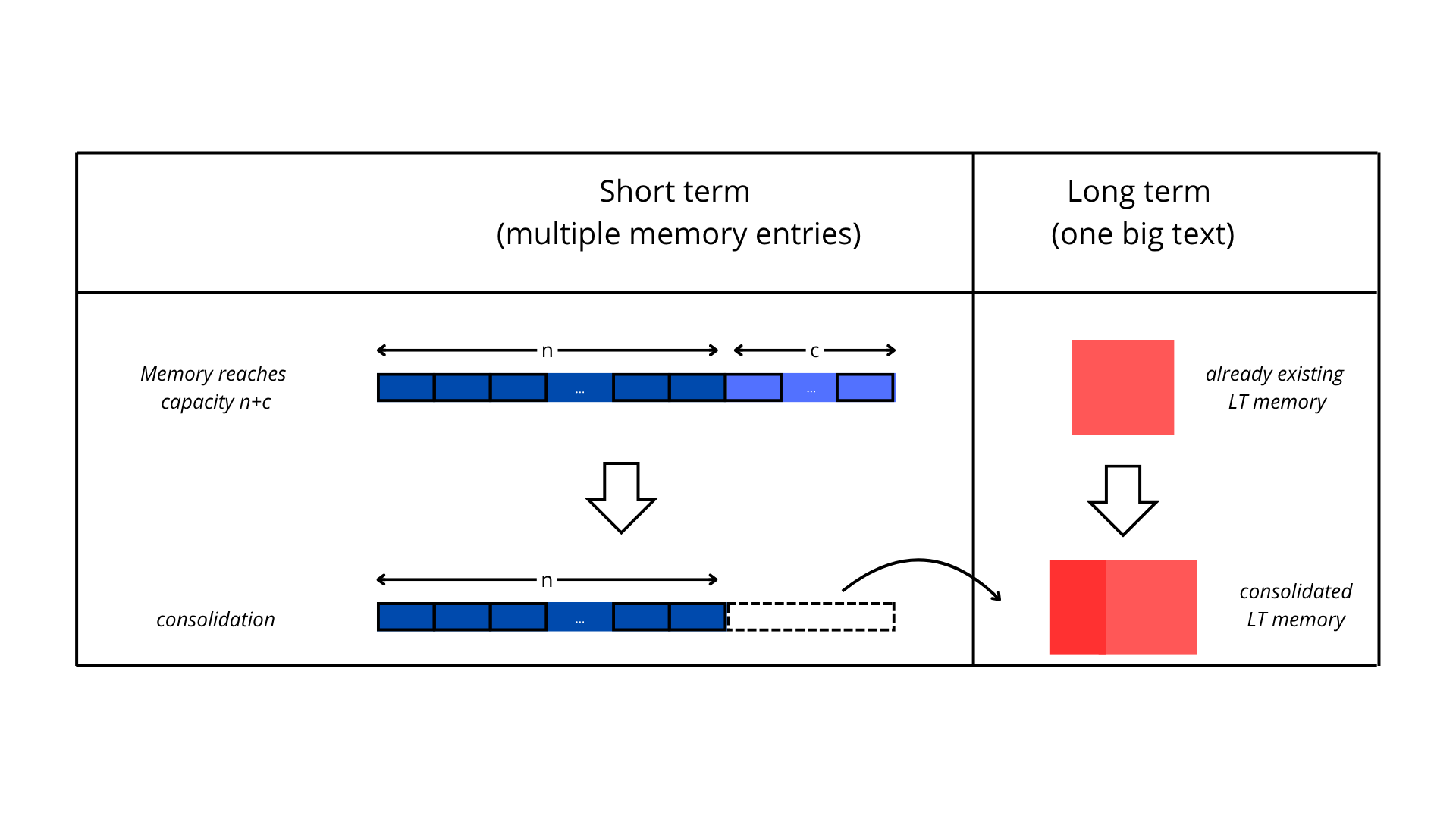
- class STLTMemory(agent: LLMAgent, short_term_capacity: int = 5, consolidation_capacity: int = 2, display: bool = True, llm_model: str | None = None, api_base: str | None = None, additive_event_types: list[str] | set[str] | tuple[str, ...] | None = None)[source]#
Bases:
MemoryImplements a dual-memory system where recent experiences are stored in short-term memory with limited capacity, and older memories are consolidated into long-term summaries using LLM-based summarization.
- Attributes:
agent : the agent that the memory belongs to
- Memory is composed of
A short term memory who stores the n (int) most recent interactions (observations, planning, discussions)
A long term memory that is a summary of the memories that are removed from short term memory (summary
completed/refactored as it goes) - Event types in
additive_event_typesaccumulate within a step.Defaults to
{"message", "action"}.- Logic behind the implementation
Short-term capacity: Configurable number of recent memory entries (default: short_term_capacity = 5)
Consolidation: When capacity is exceeded, oldest entries are summarized into long-term memory (number of entries to summarize is configurable, default: consolidation_capacity = 3)
LLM Summarization: Uses a separate LLM instance to create meaningful summaries of past experiences
Initialize the memory
- Args:
short_term_capacity : the number of interactions to store in the short term memory llm_model : the model to use for the summarization api_base : the API base URL to use for the LLM provider agent : the agent that the memory belongs to additive_event_types : event types that accumulate multiple values
within a step instead of overwriting. Defaults to
{"message", "action"}.
- class ShortTermMemory(agent: LLMAgent, n: int = 5, display: bool = True, additive_event_types: list[str] | set[str] | tuple[str, ...] | None = None)[source]#
Bases:
MemorySimple short-term memory implementation without consolidation (stores recent entries up to capacity limit). Same functionality as STLTMemory but without the long-term memory and consolidation mechanism.
- Attributes:
agent : the agent that the memory belongs to n : positive number of short-term memories to remember display : whether to display the memory llm_model : the model to use for the summarization additive_event_types : event types accumulated as lists within a step.
Defaults to
{"message", "action"}.
Initialize short-term memory.
- Args:
agent : the agent that owns this memory n : maximum number of finalized short-term entries to keep display : whether memory entries should be displayed additive_event_types : event types that accumulate multiple values
within a step instead of overwriting. Defaults to
{"message", "action"}.
- class LongTermMemory(agent: LLMAgent, display: bool = True, llm_model: str = 'openai/gpt-4o-mini', api_base: str | None = None, additive_event_types: list[str] | set[str] | tuple[str, ...] | None = None)[source]#
Bases:
MemoryPurely long-term memory class that tries to store everything the agent experiences.
- Attributes:
agent : the agent that the memory belongs to display : whether to display the memory llm_model : the model to use for the summarization additive_event_types : event types accumulated as lists within a step.
Defaults to
{"message", "action"}.
Initialize long-term memory.
- Args:
agent : the agent that owns this memory display : whether memory entries should be displayed llm_model : the model used for long-term summarization api_base : the API base URL to use for the LLM provider additive_event_types : event types that accumulate multiple values
within a step instead of overwriting. Defaults to
{"message", "action"}.
- process_step(pre_step: bool = False)[source]#
Process the step of the agent: - Merge the new entry into long term memory - Display the new entry (Will display it only when a new entry is created in this call)
- class EventGrade(*, grade: int)[source]#
Bases:
BaseModelCreate a new model by parsing and validating input data from keyword arguments.
Raises [ValidationError][pydantic_core.ValidationError] if the input data cannot be validated to form a valid model.
self is explicitly positional-only to allow self as a field name.
- model_config = {}#
Configuration for the model, should be a dictionary conforming to [ConfigDict][pydantic.config.ConfigDict].
- normalize_dict_values(scores: dict, min_target: float, max_target: float) dict[source]#
Normalize dictionary values to a target range with min-max scaling.
This mirrors the min-max helper used in the Generative Agents reference retrieval implementation: joonspk-research/generative_agents
- class EpisodicMemory(agent: LLMAgent, llm_model: str | None = None, display: bool = True, max_capacity: int = 200, considered_entries: int = 30, recency_decay: float = 0.995, api_base: str | None = None)[source]#
Bases:
MemoryEvent-level memory with LLM-based importance scoring and recency-aware retrieval.
Credit / references: - Paper: Generative Agents: Interactive Simulacra of Human Behavior
Reference retrieval code: joonspk-research/generative_agents
This implementation is inspired by the paper’s retrieval scoring design (component-wise min-max normalization, then weighted combination). It is not a strict copy of the original code: relevance scoring via embeddings is not implemented yet, and recency is computed from step age.
Initialize the EpisodicMemory.
- Args:
agent : the agent that owns this memory llm_model : the model used to grade event importance display : whether to display memory entries in the console max_capacity : maximum number of finalized episodic entries to keep considered_entries : number of entries to consider during retrieval recency_decay : exponential decay factor for recency scoring api_base : the API base URL to use for the LLM provider
- grade_event_importance(type: str, content: dict) float[source]#
Grade this event based on the content respect to the previous memory entries
- async agrade_event_importance(type: str, content: dict) float[source]#
Asynchronous version of grade_event_importance
- retrieve_top_k_entries(k: int) list[MemoryEntry][source]#
Retrieve the top-k entries using normalized importance and recency.
Notes: - Inspired by Generative Agents retrieval scoring:
recency/importance/relevance are normalized separately and combined.
This implementation currently combines importance + recency only. Relevance (embedding cosine similarity with a focal query) is pending.
- async aadd_to_memory(type: str, content: dict)[source]#
Async version of add_to_memory + grading logic